Durante nuestro último seminario, estuvimos exponiendo los trabajos finales de investigación, en concreto mi grupo, formado por Maria Luisa Varo, Andrea Vargas, Ana Sánchez y yo, lo realizamos de la educación sexual para jóvenes. Un proyecto enfocado a conocer las actitudes, creencias y conocimientos de la población acerca de ello y establecer criterios para poder disminuir las ETS y embarazos no deseados.
Antes de realizar el trabajo formal, hicimos un protocolo de la investigación, esto era un resumen a priori sobre como íbamos a enfocar nuestro trabajo y la metodología que íbamos a utilizar para llevarlo a cabo.
Finalmente gracias al trabajo conjunto, el día del seminario, la exposición que realizaron mis compañeras Maria Luisa y Ana salió bastante bien, y seguidamente al finalizar la exposición, Andrea y yo nos dedicaríamos a resolver dudas sobre el trabajo final.
En mi opinión creo que en vista al trabajo, el resultado fue notablemente mejor que el trabajo pasado y que evolucionamos de manera positiva de cara a la superación de la asignatura. Puedo decir que estoy orgullosa de haber realizado mi primer trabajo de investigación junto con mis compañeras y poder seguir así a lo largo de mi carrera.
Hasta aquí el trabajo de mi blog para la asignatura estadística, esta noche subiré una reflexión final.
Un saludo.

miércoles, 3 de junio de 2015
lunes, 1 de junio de 2015
SEMINARIO 4
Bueno, ya que estoy inspirada y hoy hemos tenido el examen me dispongo a realizar la que puede ser mi penúltima entrada.
Voy a escribir sobre el seminario 4, que se produjo el día 22 de mayo y tres días antes de nuestro quinto y último seminario en el que expondríamos nuestro trabajo de investigación. Durante este seminario, el profesor nos estuvo aclarando algunas dudas que teníamos sobre el test de hipótesis Chi-cuadrado y realizamos un problema ilustrativo en el que se entendía muy bien lo que queríamos obtener con este test de hipótesis. Además nos aclaró como debíamos mirar los datos en la tabla de representación de datos, explicando su significado y cuándo debíamos rechazar o aceptar la hipótesis nula.
Nos explicó también la diferencia entre el error alfa y el beta así como algunos conceptos que seguíamos sin entender. En realidad nos dimos cuenta de que más que difícil era laborioso y que haciendo ejercicios no costaba trabajo hacer se tipo de problemas bien.
Tras todo eso, el profesor nos dejó tiempo para poder realizar análisis estadísticos en el programa Epi Info para el lunes siguiente que teníamos que presentar el trabajo de investigación. Tuvimos que hacerlo de manera rápida y eficaz ya que contábamos con tan solo dos días para obtener los resultados, establecer conclusiones y prepararnos la exposición.
Nos enseñó como interpretar los datos para poder discutirlos con otros autores y establecer conclusiones y finalmente nos dejó el tiempo que quedaba para poder adelantar parte del trabajo.
En mi opinión este fue un seminario bastante útil y productivo ya que pudimos avanzar con el trabajo bastante y entender todos los epígrafes de él a la perfección además de comprender los resultados de los análisis realizados.

Voy a escribir sobre el seminario 4, que se produjo el día 22 de mayo y tres días antes de nuestro quinto y último seminario en el que expondríamos nuestro trabajo de investigación. Durante este seminario, el profesor nos estuvo aclarando algunas dudas que teníamos sobre el test de hipótesis Chi-cuadrado y realizamos un problema ilustrativo en el que se entendía muy bien lo que queríamos obtener con este test de hipótesis. Además nos aclaró como debíamos mirar los datos en la tabla de representación de datos, explicando su significado y cuándo debíamos rechazar o aceptar la hipótesis nula.
Nos explicó también la diferencia entre el error alfa y el beta así como algunos conceptos que seguíamos sin entender. En realidad nos dimos cuenta de que más que difícil era laborioso y que haciendo ejercicios no costaba trabajo hacer se tipo de problemas bien.
Tras todo eso, el profesor nos dejó tiempo para poder realizar análisis estadísticos en el programa Epi Info para el lunes siguiente que teníamos que presentar el trabajo de investigación. Tuvimos que hacerlo de manera rápida y eficaz ya que contábamos con tan solo dos días para obtener los resultados, establecer conclusiones y prepararnos la exposición.
Nos enseñó como interpretar los datos para poder discutirlos con otros autores y establecer conclusiones y finalmente nos dejó el tiempo que quedaba para poder adelantar parte del trabajo.
En mi opinión este fue un seminario bastante útil y productivo ya que pudimos avanzar con el trabajo bastante y entender todos los epígrafes de él a la perfección además de comprender los resultados de los análisis realizados.
SEMINARIO 3
Durante el seminario 3 de la asignatura, el profesor nos estuvo explicando y resolviendo las dudas sobre el tema 8 dado en clase aquel día.
Antes que nada, nos metimos en el programa Epi Info que ya expliqué anteriormente para realizar los análisis estadísticos del trabajo final. Tras ello y visto que la mayoría de personas estábamos muy agobiadas de cara al examen, el profesor nos explicó poco a poco todas las medidas de tendencia central, posición y dispersión mediante una presentación de power point con la que nos quedó todo mucho más claro.
Después de explicar toda la teoría, estuvimos viendo ejemplos de los tipos de asimetría existentes con sus respectivos resultados y con las medidas de aplanamiento o curtosis. Esto último si me resultó de más complicación.
Finalmente nos dispusimos a seguir aprendiendo a utilizar Epi Info para el trabajo final de investigación.
Gracias a este seminario, pudimos además de adelantar materia, entender la que llevábamos hasta el momento y entender conceptos que aunque se hayan dado desde siempre y parecían entendidos, no lo eran hasta ese día.
Antes que nada, nos metimos en el programa Epi Info que ya expliqué anteriormente para realizar los análisis estadísticos del trabajo final. Tras ello y visto que la mayoría de personas estábamos muy agobiadas de cara al examen, el profesor nos explicó poco a poco todas las medidas de tendencia central, posición y dispersión mediante una presentación de power point con la que nos quedó todo mucho más claro.
Después de explicar toda la teoría, estuvimos viendo ejemplos de los tipos de asimetría existentes con sus respectivos resultados y con las medidas de aplanamiento o curtosis. Esto último si me resultó de más complicación.
Finalmente nos dispusimos a seguir aprendiendo a utilizar Epi Info para el trabajo final de investigación.
Gracias a este seminario, pudimos además de adelantar materia, entender la que llevábamos hasta el momento y entender conceptos que aunque se hayan dado desde siempre y parecían entendidos, no lo eran hasta ese día.
sábado, 30 de mayo de 2015
TABLA DE DISTRIBUCIÓN NORMAL TIPIFICADA Y TABLA DE VALORES CHI-2

Os dejo la tabla de distribución normal tipificada para la realización de problemas.



También la tabla de valores de chi cuadrado, recordad que si el valor que os da es mayor que el que está en la tabla para un determinado error, hay que rechazar la hipótesis nula!!!!
TEMA 10. HIPÓTESIS ESTADÍSTICAS. TEST DE HIPÓTESIS
Bueno, este fue el último tema que vimos en clase, en concreto el chi cuadrado.
Para controlar los errores aleatorios, además de los intervalos de confianza, contamos con otra herramienta como es el test o contraste de hipótesis.
Con los intervalos nos hacemos una idea de un parámetro de una población dado un par de números entre los que confiamos que esté el valor desconocido.
Son herramientas estadísticas para responder a preguntas de investigación, cuantifica la relación entre una hipótesis previamente establecida y los resultados obtenidos. El test de hipótesis siempre va a contrastar la hipótesis nula (la que no establece relación entre las variables).
Hay varios tipos de análisis estadísticos según el tipo de variables implicadas en el estudio aunque nosotros solo podemos investigar con chi cuadrado.

El test de hipótesis mide la variabilidad de error que cometo si rechazo la hipótesis nula. Con una misma muestra, podemos aceptar o rechazar la hipótesis nula. Todo ello depende de dos errores que podemos cometer.
El error alfa es la probabilidad de equivocarnos al rechazar la hipótesis nula, es decir rechazarla siendo ésta verdadera.
El error beta es la probabilidad de equivocarnos al aceptar la hipótesis nula, es decir, aceptarla siendo falsa.
Es lo que llamamos significación estadística.

https://www.youtube.com/watch?v=-osaBBWFIDk
Para controlar los errores aleatorios, además de los intervalos de confianza, contamos con otra herramienta como es el test o contraste de hipótesis.
Con los intervalos nos hacemos una idea de un parámetro de una población dado un par de números entre los que confiamos que esté el valor desconocido.
Son herramientas estadísticas para responder a preguntas de investigación, cuantifica la relación entre una hipótesis previamente establecida y los resultados obtenidos. El test de hipótesis siempre va a contrastar la hipótesis nula (la que no establece relación entre las variables).
Hay varios tipos de análisis estadísticos según el tipo de variables implicadas en el estudio aunque nosotros solo podemos investigar con chi cuadrado.
El error alfa es la probabilidad de equivocarnos al rechazar la hipótesis nula, es decir rechazarla siendo ésta verdadera.
El error beta es la probabilidad de equivocarnos al aceptar la hipótesis nula, es decir, aceptarla siendo falsa.
Es lo que llamamos significación estadística.
- Test de hipótesis Chi-cuadrado
En primer lugar suponemos la hipótesis cierta y estudiamos como es de probable que siendo iguales dos grupos a comparar se obtengan resultados como los obtenidos o haber encontrado diferencias más grandes por grupos.
Para ello voy a poner un ejemplo explicado con el que seguramente lo entendáis mejor.https://www.youtube.com/watch?v=-osaBBWFIDk
TEMA 9. ESTADÍSTICA INFERENCIAL. MUESTREO Y ESTIMACIÓN
Bueno, pues llegados a este punto, puede decirse que este es el tema de mayor importancia dentro de la asignatura ya que abarca numerosos puntos, todos ellos fundamentales para la realización de problemas.
Este tema puede encasillarse en varios puntos importantes: cálculo del error estándar y Teorema central del límite, intervalos de confianza y finalmente el muestreo (tipos y cálculo de tamaños muestrales).
Para empezar, voy a explicar algunos conceptos previos a los cálculos. Por un lado, la población de estudio, que es el conjunto de pacientes o individuos sobre los que queremos estudiar alguna cuestión y se distingue de muestra en que ésta son los individuos concretos que participan en el estudio. Siendo el conjunto de ellos el tamaño muestral.
Al conjunto de procedimientos que permiten pasar de lo particular de la muestra a lo general, la población, le denominamos inferencia estadística o con palabras cotidianas ''extrapolar''.
Finalmente señalar la diferencia entre un parámetro que es la medida que queremos obtener, y un estimador que es la variable de estudio obtenida en la muestra.
Cuanto más pequeño es el error estándar de un estimador, más nos podemos fiar del valor de una muestra concreta.
Para calcularlo debemos diferenciar si se trata de una media o una proporción. Siendo para una media la fórmula que aparece en primer lugar y para una proporción la de abajo.
s= desviación típica.
n=tamaño de la población.
p=proporción del estimador.
De ambas fórmulas se deduce que a mayor tamaño de la muestra, menor será el error que cometamos.
Si sigue una distribución normal como ya dije en anteriores entradas, 1S abarca un 68,26% de las observaciones, 2S un 95,45% de las observaciones y 3S un 99%.
Se trata de un par de números tales que, con un nivel de confianza determinados, podemos asegurar que el valor del parámetro es mayor que el límite inferior y menor que el superior.
Se calcula considerando que el estimador muestral sigue una distribución normal, como establece la teoría central del límite mediante la siguiente fórmula.
Siendo la p la proporción o la media X , Z el valor que depende el intervalo de confianza que nos piden (95%- z=1,96) (99%- z=2,58).
El signo significa que cuando elija el signo negativo se conseguirá el límite inferior y cuando se elija el positivo se tendrá el extremo superior.
Mientras mayor sea la confianza que queramos otorgar al intervalo, éste será más amplio, es decir, los extremos estarán más distanciados y por tanto el intervalo será menos preciso.
La población general de la que queremos obtener conclusiones las vamos a elegir al azar, para obtener la muestra y a partir de esta hacer inferencia de la población entera.
Encontramos diferentes tipos, el probabilístico en el que todos los sujetos de la población tienen una probabilidad distinta de cero en la selección de la muestra. Dentro de este grupo se encuentran: el aleatorio simple, aleatorio sistemático, estratificado, conglomerado y multietápico.
Por otro lado el no probabilístico en el que se sitúan el accidental o por cuotas y finalmente el de conveniencia del estimador.
Para una media:
 Siendo Z el valor que depende del nivel de confianza, S la desviación típica y E el error máximo aceptado por los investigadores. Todo ello elevado al cuadrado. (desviación típica al cuadrado= varianza)
Siendo Z el valor que depende del nivel de confianza, S la desviación típica y E el error máximo aceptado por los investigadores. Todo ello elevado al cuadrado. (desviación típica al cuadrado= varianza)
Para una proporción:

Datos iguales a la anterior fórmula siendo N el tamaño de la población y p la proporción.
Se redondea siempre hacia arriba el número de sujetos de la muestra.
Espero que se entienda, al final de todo pondré varios ejemplos de cada tipo de fórmula para practicar. A trabajar!!!!!
Este tema puede encasillarse en varios puntos importantes: cálculo del error estándar y Teorema central del límite, intervalos de confianza y finalmente el muestreo (tipos y cálculo de tamaños muestrales).
Para empezar, voy a explicar algunos conceptos previos a los cálculos. Por un lado, la población de estudio, que es el conjunto de pacientes o individuos sobre los que queremos estudiar alguna cuestión y se distingue de muestra en que ésta son los individuos concretos que participan en el estudio. Siendo el conjunto de ellos el tamaño muestral.
Al conjunto de procedimientos que permiten pasar de lo particular de la muestra a lo general, la población, le denominamos inferencia estadística o con palabras cotidianas ''extrapolar''.
Finalmente señalar la diferencia entre un parámetro que es la medida que queremos obtener, y un estimador que es la variable de estudio obtenida en la muestra.
- Error estándar
 |
| Error de una media |
 |
| Error de una proporción |
s= desviación típica.
n=tamaño de la población.
p=proporción del estimador.
De ambas fórmulas se deduce que a mayor tamaño de la muestra, menor será el error que cometamos.
- Teorema central del límite
Si sigue una distribución normal como ya dije en anteriores entradas, 1S abarca un 68,26% de las observaciones, 2S un 95,45% de las observaciones y 3S un 99%.
- Intervalos de confianza
 |
| IC de una media |
Se calcula considerando que el estimador muestral sigue una distribución normal, como establece la teoría central del límite mediante la siguiente fórmula.
 |
| IC de una proporción |
Siendo la p la proporción o la media X , Z el valor que depende el intervalo de confianza que nos piden (95%- z=1,96) (99%- z=2,58).
El signo significa que cuando elija el signo negativo se conseguirá el límite inferior y cuando se elija el positivo se tendrá el extremo superior.
Mientras mayor sea la confianza que queramos otorgar al intervalo, éste será más amplio, es decir, los extremos estarán más distanciados y por tanto el intervalo será menos preciso.
- Muestreo y tipos
La población general de la que queremos obtener conclusiones las vamos a elegir al azar, para obtener la muestra y a partir de esta hacer inferencia de la población entera.
Encontramos diferentes tipos, el probabilístico en el que todos los sujetos de la población tienen una probabilidad distinta de cero en la selección de la muestra. Dentro de este grupo se encuentran: el aleatorio simple, aleatorio sistemático, estratificado, conglomerado y multietápico.
Por otro lado el no probabilístico en el que se sitúan el accidental o por cuotas y finalmente el de conveniencia del estimador.
- Tamaño muestral
Para una media:
Para una proporción:
Datos iguales a la anterior fórmula siendo N el tamaño de la población y p la proporción.
Se redondea siempre hacia arriba el número de sujetos de la muestra.
Espero que se entienda, al final de todo pondré varios ejemplos de cada tipo de fórmula para practicar. A trabajar!!!!!
CONTINUACIÓN. DISTRIBUCIONES NORMALES Y TIPIFICACIÓN DE VALORES
Como dije en la anterior entrada, voy a continuar describiendo el tema 8, en concreto las distribuciones normales y la tipificación de valores. Esto último de gran importancia de cara a los posibles problemas del examen.
Distribuciones normales
En estadística las distribuciones normales, también conocidas como distribución de Gauss o gaussiana, son distribuciones de probabilidad de variable continua que con más frecuencia aparece en fenómenos reales.
La gráfica tiene una vista acampanada y simétrica respecto a los valores de posición central (media, mediana y moda) que en estas distribuciones coinciden.




Distribuciones normales
En estadística las distribuciones normales, también conocidas como distribución de Gauss o gaussiana, son distribuciones de probabilidad de variable continua que con más frecuencia aparece en fenómenos reales.
La gráfica tiene una vista acampanada y simétrica respecto a los valores de posición central (media, mediana y moda) que en estas distribuciones coinciden.

La gráfica anterior se conoce como campana de Gauss y tiene las siguientes características: al sumarle una desviación típica a ambos lados, se obtienen el 68,26% de las observaciones, si se le suman dos, un 95,45% de las observaciones y si le sumamos tres desviaciones, un 99% de las mismas.
Por otro lado se encuentran las simetrías y curtosis.
La asimetría se mira según el lado contrario al que se encuentre el pico de la curva, es decir, si el pico se encuentra a la derecha es asimetría a la izquierda y viceversa.
Esto nos sirve para ver es grado de asimetría de una variable que no es más que la distribución de los datos en torno a su media.
Los resultados pueden ser los siguientes:
- g1=0. Distribución simétrica, existen la misma concentración de valores a la derecha y a la izquierda de la media.
- g1>0. Distribución asimétrica positiva, existe una mayor concentración de valores a la derecha que a la izquierda de la media.
- g1<0. Distribución asimétrica negativa, existe una mayor concentración de valores a la izquierda que a la derecha de la media.
Los resultados pueden ser los siguientes:
- g2=0. Distribución mesocúrtica. Presenta un grado de concentración medio alrededor de los valores centrales de la variable.
- g2>0. Distribución leptocúrtica. Presenta un elevado grado de concentración alrededor de los valores centrales de la variable.
- g2<0. Distribución platicúrtica. Presenta un reducido grado de concentración alrededor de los valores centrales de la variable.


Tipificación de valores
Para ello utilizaremos variables que tienen una distribución normales y compararlos con una tabla de valores ya establecida. Lo único que debe reunir es que sigan una distribución normal y que tengan más de 100 unidades.
La tipificación de valores o normalización nos permite conocer si otro valor corresponde o no a esa distribución de frecuencia.
Para ello voy a poner un ejemplo:
En una muestra de 500 mujeres que reciben asistencia queremos saber como la pobreza afecta a su autoestima.
Medimos la autoestima con una escala de actitud de 20 puntos (variable continua). Suponemos que la distribución sigue una curva normal.
Media autoestima: 8
Desviación típica: 2
Nos preguntan, ¿Qué porcentaje de las destinatarias de la asistencia tienen puntuaciones de autoestima entre 5 y 8?
Para hallarlos hay que transformar las puntuaciones en tipificadas (Z).
Nos vamos a la tabla de la distribución normal y buscamos 1,50 que sale 0,4332, en % 43,32.
O lo que es lo mismo: un poco más del 43% de las destinatarias de asistencia están entre 5 y 8 de autoestima
O si una persona selecciona al azar hay un 43% de posibilidades que la persona tenga una autoestima entre 5 y 8.
Espero que os haya sido de utilidad, si me da tiempo pondré más ejemplos de este tipo en otras entradas.
viernes, 29 de mayo de 2015
TEMA 8. MEDIDAS DE TENDENCIA CENTRAL, POSICIÓN Y DISPERSIÓN
Durante las clases del tema 8, estuvimos viendo las medidas de tendencia central, posición y dispersión.
Por un lado se encuentran las medidas de posición que nos indican la magnitud o tamaño de los datos y lo que establecen principalmente es la posición de un individuo dentro de una muestra o serie estadística.
Dentro de éstas se sitúan los cuantiles, siendo los más habituales los percentiles que dividen a la muestra ordenada en 100 partes, aunque también se encuentran los deciles (10 partes) ó cuartiles (en 4 partes).
Las medidas de tendencia central por otra parte, nos indican el comportamiento de la mayoría de los sujetos. Dentro de ésta están datos estadísticos que hemos utilizado desde la infancia como son la media, mediana y moda.
Finalmente se encuentran las medidas de dispersión, dentro de ellas se encuentra el rango o recorrido, que no es más que la diferencia entre el valor mayor y el menor de la muestra [Xn-X1], la desviación típica, que se presenta como la media aritmética de las distancias de cada observación con respecto a la media de la muestra que se diferencia de la desviación media o estándar en que ésta cuantifica el error que cometeríamos si representáramos un muestra únicamente con su media.



La varianza que es el cuadrado de la desviación tipica y el coeficiente de variación que es la diferencia entre la desviación tipica y la media.
Bueno y para no ser muy pesada con este tema que tiene lo suyo, la parte final de las distribuciones normales y tipificación voy a ponerla en otra entrada, para que no se creen dudas sobre lo anterior y entenderlo lo mejor posible.
Por un lado se encuentran las medidas de posición que nos indican la magnitud o tamaño de los datos y lo que establecen principalmente es la posición de un individuo dentro de una muestra o serie estadística.
Dentro de éstas se sitúan los cuantiles, siendo los más habituales los percentiles que dividen a la muestra ordenada en 100 partes, aunque también se encuentran los deciles (10 partes) ó cuartiles (en 4 partes).
Las medidas de tendencia central por otra parte, nos indican el comportamiento de la mayoría de los sujetos. Dentro de ésta están datos estadísticos que hemos utilizado desde la infancia como son la media, mediana y moda.
- La media se calcula para hallar el centro geométrico de las variables cuantitativas, es la suma de todos los valores dividida entre el número de observaciones. Sin embargo ésto solo nos funciona cuando los datos están desagrupados, cuando nos encontramos ante una tabla de frecuencia por ejemplo, en la que los datos están agrupados, la fórmula de la media es diferente, siendo en este caso el sumatorio de las marcas de clase por la frecuencia absoluta dividida entre el número de observaciones.


- La mediana por otro lado es el dato que deja al 50% de los demás por encima y al otro 50% por debajo. Aspecto a tener en cuenta es que si los datos son pares, la mediana será la media de los dos valores centrales, si son impares el valor será el que ocupe la posición n+1/2.Destaca de ella que es una medida tanto de tendencia central como de posición.
- La moda, se utiliza tanto para datos cuantitativos como cualitativos, pero precisa de una desagrupación de los datos. Es el valor con mayor frecuencia, o dicho de otro modo ''el que más se repite''. Si los datos están agrupados se habla de intervalo modal y corresponde al intervalo en el que el cociente de la frecuencia relativa y la amplitud es mayor. También puede observarse donde la frecuencia absoluta es mayor.
La varianza que es el cuadrado de la desviación tipica y el coeficiente de variación que es la diferencia entre la desviación tipica y la media.
Bueno y para no ser muy pesada con este tema que tiene lo suyo, la parte final de las distribuciones normales y tipificación voy a ponerla en otra entrada, para que no se creen dudas sobre lo anterior y entenderlo lo mejor posible.
domingo, 17 de mayo de 2015
TEMA 7. INTRODUCCIÓN A LA BIOESTADÍSTICA
Durante el tema 7, comenzamos a ponernos en marcha con los problemas y para ello lo primero que debíamos saber el concepto de estadística. La estadística es el cuerpo de conocimientos para aprender
de la experiencia, frecuentemente en de forma de números
provenientes de medias que muestran variaciones entre los diferentes
individuos. Parte del supuesto de que las
características clínicas que se observan cambian de un paciente a
otro: las variable. Éstas pueden ser de dos tipos según el punto de vista de la medición.
En primer lugar se encuentran las variables cualitativas que se refieren a propiedades que no pueden ser medidas como el nivel de conocimientos o el estado civil y por otro lado variables cuantitativas que miden términos numéricos. Éstas últimas pueden ser discretas si solo pueden tomar un número finito de valores como el número de hijos, o continuas si pueden ser divididas de forma infinita como la talla, la tensión arterial etc..
Ambas categorías deben ser exhaustas y exclusivas.
Una vez que tenemos diferenciadas las variables, es hora de ponerlas ordenadas y de forma visiblemente clara representando los datos, y esto es elaborando una tabla de frecuencia. Para ello os pongo un ejemplo y os detallo cómo hay que hacerlo.
Por ejemplo, obtenemos los pesos en kg de niños atendidos en una consulta y queremos ordenarlos y clasificar en intervalos.

Al ser variables continuas debemos poner paréntesis y corchetes en los extremos de cada intervalo para excluirlos del siguiente.
Como se observa, la fi o frecuencia absoluta es el número de niños de la muestra que se encuentran en ese intervalo de peso, y la Fi es la frecuencia absoluta acumulada que se averigua sumando los valores de fi. Ejemplo: Fi 2= 3+8= 11, Fi 3= 11+14=25
La hi es la frecuencia relativa que se halla dividiendo la frecuencia absoluta entre el número total de la muestra (fi/N). La Hi es el porcentaje y para comprobarlo debemos sumarlos todos y que el resultado sea el 100%.
Otro punto importante del tema es la representación de gráficas, que son la imagen de las ideas o forma de representación numérica. Entre las más importantes destacan: el diagrama de barra, el pictograma (variante del diagrama de barra), el histograma, el gráfico de tronco y hojas, gráfico de sectores y finalmente el gráfico para datos bidimensionales y multidimensionales.
Para no extenderme mucho voy a hacer un pequeño resumen de lo más importante de cada uno.
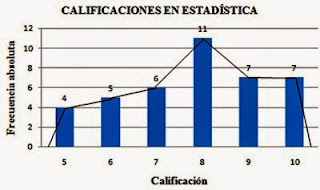 El polígono de frecuencia se realiza haciendo las marcas de clase que es el resultado de la media entre la suma de los dos extremos de cada intervalo.
El polígono de frecuencia se realiza haciendo las marcas de clase que es el resultado de la media entre la suma de los dos extremos de cada intervalo.

En primer lugar se encuentran las variables cualitativas que se refieren a propiedades que no pueden ser medidas como el nivel de conocimientos o el estado civil y por otro lado variables cuantitativas que miden términos numéricos. Éstas últimas pueden ser discretas si solo pueden tomar un número finito de valores como el número de hijos, o continuas si pueden ser divididas de forma infinita como la talla, la tensión arterial etc..
Ambas categorías deben ser exhaustas y exclusivas.
Una vez que tenemos diferenciadas las variables, es hora de ponerlas ordenadas y de forma visiblemente clara representando los datos, y esto es elaborando una tabla de frecuencia. Para ello os pongo un ejemplo y os detallo cómo hay que hacerlo.
Por ejemplo, obtenemos los pesos en kg de niños atendidos en una consulta y queremos ordenarlos y clasificar en intervalos.
Pesos En Kg De
Niños Atendidos En La Consulta De Niño Sano. N = 40
5,3 3,9 4.3 5.0 6.0 4.7 5.1 4.2 4.4 5.8
3.3 4.3 4.1 5.8 4.4 4.8 6.1 4.3 5.3 4.5
4.0 5.4 3.9 4.7 3.3 4.5 4.7 4.2 4.5 4.8
En primer lugar lo que haremos será buscar el peso mayor y el peso menor del grupo de datos para así averiguar el rango o recorrido de la muestra. En este caso:
El que más pesa tiene un peso de 6,1 Kg y el que menos pesa tiene un peso de 3,3 Kg, por lo que el recorrido es 6,1-3,3= 2,8
A continuación, para calcular el número de intervalos en los que los vamos a dividir le hacemos la raíz cuadrada al número total de individuos de la muestra y vemos que la raíz de 40 es 6,32. Por tanto los clasificaremos en 6 intervalos.
Al ser el recorrido 2,8 lo dividiremos entre el número de intervalos para así saber la amplitud de dicho intervalo que en este caso será 2,8/6= 0,46
Tras estos pasos, podemos proceder a realizar la tabla de frecuencia.
Al ser variables continuas debemos poner paréntesis y corchetes en los extremos de cada intervalo para excluirlos del siguiente.
Como se observa, la fi o frecuencia absoluta es el número de niños de la muestra que se encuentran en ese intervalo de peso, y la Fi es la frecuencia absoluta acumulada que se averigua sumando los valores de fi. Ejemplo: Fi 2= 3+8= 11, Fi 3= 11+14=25
La hi es la frecuencia relativa que se halla dividiendo la frecuencia absoluta entre el número total de la muestra (fi/N). La Hi es el porcentaje y para comprobarlo debemos sumarlos todos y que el resultado sea el 100%.
Otro punto importante del tema es la representación de gráficas, que son la imagen de las ideas o forma de representación numérica. Entre las más importantes destacan: el diagrama de barra, el pictograma (variante del diagrama de barra), el histograma, el gráfico de tronco y hojas, gráfico de sectores y finalmente el gráfico para datos bidimensionales y multidimensionales.
Para no extenderme mucho voy a hacer un pequeño resumen de lo más importante de cada uno.
- Diagrama de barra Se utilizan para medir variables cualitativas, nominales y policotómicas. Una variante de éste es el pictograma que se diferencia del diagrama en que se sustituyen las barras por iconos referidas a lo que estamos estudiando pero no aportan información adicional.

- Histograma y polígonos de frecuencia Solo se usa para variables continuas y en este caso los dos ejes no proporcionan información. Si la amplitud del intervalo es la misma, las columnas irán juntas, de lo contrario habrá que ajustar el área del rectángulo según una proporción.
 El polígono de frecuencia se realiza haciendo las marcas de clase que es el resultado de la media entre la suma de los dos extremos de cada intervalo.
El polígono de frecuencia se realiza haciendo las marcas de clase que es el resultado de la media entre la suma de los dos extremos de cada intervalo.- Gráfico de tronco (o tallo) y hojas Se utiliza para expresar variables cuantitativas continuas. Es un híbrido entre la tabla y el histograma: nos muestra la forma de la distribución y los valores de la variable. Cada dato de la seria se divide en tres partes: tronco(decenas), las ramas (centenas) y la hoja (unidades).
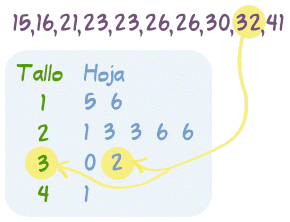
 Gráfico de sectores Se utilizan para variables cualitativas y con pocas categorías preferentemente dicotómicas.
Gráfico de sectores Se utilizan para variables cualitativas y con pocas categorías preferentemente dicotómicas.
- Gráfico de datos bidimensionales y multidimensionales
 Son gráficos en los que se representan varias variables al mismo tiempo. Suelen mezclar variables cualitativas y continuas.
Son gráficos en los que se representan varias variables al mismo tiempo. Suelen mezclar variables cualitativas y continuas.


Diagrama de estrella (estadística avanzada)
viernes, 8 de mayo de 2015
SEMINARIO 2
Durante la sesión del seminario 2, en primer lugar procedimos a exponer las búsquedas bibliográficas avanzadas de los tres casos, y más tarde aprendimos a utilizar un programa llamado Epi Info que utilizaremos para el trabajo final de investigación en los próximos seminarios.
Con este programa entre otras cosas, se pueden crear formularios, muy útiles en el ámbito de la investigación, y posteriormente grabar los datos obtenidos.

 Una vez dentro del programa, aprendimos a establecer un título a nuestro caso en la hoja de diseño, dentro del apartado título, y nos dirigimos a donde pone ''texto''. Tras esto, podemos empezar a añadir las preguntas a nuestro cuestionario. Éstas pueden ser preguntas de Si/No, preguntas con respuesta excluyente (dentro del apartado option) ó preguntas de respuesta múltiple (en checkbox). Todo ello para acotar nuestros resultados y obtener datos en un rango estrecho.
Una vez dentro del programa, aprendimos a establecer un título a nuestro caso en la hoja de diseño, dentro del apartado título, y nos dirigimos a donde pone ''texto''. Tras esto, podemos empezar a añadir las preguntas a nuestro cuestionario. Éstas pueden ser preguntas de Si/No, preguntas con respuesta excluyente (dentro del apartado option) ó preguntas de respuesta múltiple (en checkbox). Todo ello para acotar nuestros resultados y obtener datos en un rango estrecho.
Una vez terminado el cuestionario, para guardarlo y grabar los datos le damos a Enter Data.
El seminario nos ha sido muy útil ya que gracias a este programa podemos realizar la investigación del trabajo final y encontrar datos suficientes para realizar el análisis estadístico. Espero que lo encontréis igual de práctico que yo.
Con este programa entre otras cosas, se pueden crear formularios, muy útiles en el ámbito de la investigación, y posteriormente grabar los datos obtenidos.
Una vez dentro del programa, aprendimos a establecer un título a nuestro caso en la hoja de diseño, dentro del apartado título, y nos dirigimos a donde pone ''texto''. Tras esto, podemos empezar a añadir las preguntas a nuestro cuestionario. Éstas pueden ser preguntas de Si/No, preguntas con respuesta excluyente (dentro del apartado option) ó preguntas de respuesta múltiple (en checkbox). Todo ello para acotar nuestros resultados y obtener datos en un rango estrecho.Una vez terminado el cuestionario, para guardarlo y grabar los datos le damos a Enter Data.
El seminario nos ha sido muy útil ya que gracias a este programa podemos realizar la investigación del trabajo final y encontrar datos suficientes para realizar el análisis estadístico. Espero que lo encontréis igual de práctico que yo.
domingo, 3 de mayo de 2015
TEMA 6. ETAPA EMPÍRICA DE LA INVESTIGACIÓN.
Durante las clases que componían el tema 6, y una vez hecho el marco teórico, debemos clasificar el estudio teniendo en cuenta estos cuatro parámetros:
FINALIDAD: Analítico, descriptivo o experimental.
SECUENCIA TEMPORAL: transversal o longitudinal.
CONTROL DE LA ASIGNACIÓN DE LOS FACTORES DE ESTUDIO: Experimental u observacional.
CRONOLOGÍA: prospectivo o retrospectivo.
FINALIDAD: Analítico, descriptivo o experimental.
SECUENCIA TEMPORAL: transversal o longitudinal.
CONTROL DE LA ASIGNACIÓN DE LOS FACTORES DE ESTUDIO: Experimental u observacional.
CRONOLOGÍA: prospectivo o retrospectivo.
Elegidos estos parámetros, ya nos podemos dirigir a elegir el tipo de estudio. La clasificación de estudios os la dejo en la siguiente imagen.

¿Qué queremos medir?
Aquí empiezan los cálculos:
Si queremos medir la situación de un punto en el tiempo, hay que medir la prevalencia.
Si queremos medir lo que está pasando durante un periodo de tiempo, hay que medir la incidencia.
Si queremos medir lo que está pasando durante un periodo de tiempo, hay que medir la incidencia.
La prevalencia describe
qué proporción de la población tiene la enfermedad en un punto
específico en el tiempo. Esto se halla calculando el nº de individuos con la
enfermedad en un tiempo específico/nº de individuos en la población
en un punto en el tiempo. Adopta siempre valores entre 0 y 1.
La incidencia describe la
frecuencia de nuevos casos que ocurren durante un periodo de tiempo. Es el flujo de sanos a enfermos. Ésta se halla calculando el nº de nuevos casos
detectados durante el seguimiento que desarrollan la enfermedad/nº
de sujetos libre de enfermedad al comienzo del seguimiento. Adopta valores entre 0 e infinito (es una tasa).
Os dejo una foto con las fórmulas para que os aclaréis.
sábado, 25 de abril de 2015
TEMA 5. MARCO TEÓRICO, OBJETIVOS E HIPÓTESIS DE LA INVESTIGACIÓN
Durante las clases en las que analizamos el tema 5, procedimos a definir y formular los objetivos, es decir, a dónde queremos llegar con la investigación, qué es lo que queremos lograr.
Para ello en primer lugar debíamos establecer una hipótesis que no es otra cosa que las expectativas de la investigación acerca de las relaciones entre las variables que se indagan o dicho de otra manera, una predicción del estado esperado.
Por otro lado, para contextualizar el marco teórico, debemos primero formular una pregunta a partir del problema que se presente en un paciente, localizar hallazgos en la literatura, evaluarlos y finalmente sacar conclusiones de ellos para llevarlos a la práctica. Todo ello como ya he explicado en anteriores entradas puede realizarse a través de búsquedas bibliográficas en bases de datos científicas (Scopus, Pubmed,..).
Para evaluar los resultados encontrados, en primer lugar hay que determinar el nivel de evidencia que poseen, por ello existen tres tipos de diseños.
Por un lado el diseño descriptivo que solo se refiere al nivel de prevalencia de cada variable, por otro los diseños experimentales que se basan en ensayos clínicos y finalmente los diseños analíticos en los que se encuentran dos subgrupos: los estudios de cohorte o de seguimiento y los estudios de casos y controles.
Los de cohorte o de seguimiento se tratan de estudios sobre un grupo de personas con una característica en común, por ejemplo estudiantes de enfermería en Cruz Roja, y pueden ser prospectivos en los que se establece la variable independiente y la dependiente se estudia a lo largo del tiempo, por ejemplo la evolución de enfermedades respiratorias de los estudiantes fumadores vs estudiantes no fumadores.
O retrospectivo si esa variable es sobre una cohorte antigua, de hace años.
Finalmente los de casos y controles que se parte de una variable dependiente hacia la independiente.

Para ello en primer lugar debíamos establecer una hipótesis que no es otra cosa que las expectativas de la investigación acerca de las relaciones entre las variables que se indagan o dicho de otra manera, una predicción del estado esperado.
Por otro lado, para contextualizar el marco teórico, debemos primero formular una pregunta a partir del problema que se presente en un paciente, localizar hallazgos en la literatura, evaluarlos y finalmente sacar conclusiones de ellos para llevarlos a la práctica. Todo ello como ya he explicado en anteriores entradas puede realizarse a través de búsquedas bibliográficas en bases de datos científicas (Scopus, Pubmed,..).
Para evaluar los resultados encontrados, en primer lugar hay que determinar el nivel de evidencia que poseen, por ello existen tres tipos de diseños.
Por un lado el diseño descriptivo que solo se refiere al nivel de prevalencia de cada variable, por otro los diseños experimentales que se basan en ensayos clínicos y finalmente los diseños analíticos en los que se encuentran dos subgrupos: los estudios de cohorte o de seguimiento y los estudios de casos y controles.
Los de cohorte o de seguimiento se tratan de estudios sobre un grupo de personas con una característica en común, por ejemplo estudiantes de enfermería en Cruz Roja, y pueden ser prospectivos en los que se establece la variable independiente y la dependiente se estudia a lo largo del tiempo, por ejemplo la evolución de enfermedades respiratorias de los estudiantes fumadores vs estudiantes no fumadores.
O retrospectivo si esa variable es sobre una cohorte antigua, de hace años.
Finalmente los de casos y controles que se parte de una variable dependiente hacia la independiente.
jueves, 16 de abril de 2015
TEMA 4. FUENTES DE INFORMACIÓN DE CAMPO E INFORMACIÓN DOCUMENTAL
Durante las clases que comprendían el tema 4, estuvimos hablando de las diferentes fuentes de información existentes.
Por un lado se encuentran las fuentes de observación directa entre las que se encuentran las entrevistas y cuestionarios, el registro del propio paciente o los registros previos (su historia clínica,familiar..).
En primer lugar hay que explicar las diferencias entre una entrevista y un cuestionario ya que se trata de fuentes de información distintas, en una entrevista la respuesta es más abierta, da lugar a varias interpretaciones, es más subjetiva. En el cuestionario en cambio la mayor parte de las preguntas tiene un numero de respuestas limitado. No obstante ambas fuentes de información tienen una serie de ventajas e inconvenientes de gran utilidad a la hora de elaborar un protocolo o trabajo de investigación.
Dentro de la entrevista nos encontramos con una amplia gama de elección de cara a la elaboración, por un lado las estructuradas que son fáciles de elaborar y no precisan de un entrenamiento previo del entrevistador o investigador en nuestro caso. Y por otro las no estructuradas en las que se puede profundizar más en el tema y se obtienen variables y orientaciones sobre las hipótesis. Ambas tienen como inconvenientes que precisan de mucho tiempo de preparación y una cierta imposibilidad de acceder a información confidencial del usuario.
 Por otro lado, los cuestionarios son instrumentos de fácil acceso a determinada información sobre la población, tienen bajo costo y nos permiten obtener información sobre un mayor número de personas en un tiempo inferior a la entrevista.
Por otro lado, los cuestionarios son instrumentos de fácil acceso a determinada información sobre la población, tienen bajo costo y nos permiten obtener información sobre un mayor número de personas en un tiempo inferior a la entrevista.
Finalmente se encuentra el registro del propio paciente, por ejemplo queremos hacer un estudio sobre hábitos nutricionales y le decimos al paciente que vaya registrando lo que va comiendo a lo largo de la semana otro ejemplo sería su registro diario sobre la glucemia. También podemos obtener la información de un informador directo: no es el paciente sino una persona que se hace cargo de él; los tutores de un niño, el cuidador o cuidadora etc.
¿Errores que se pueden cometer? Hay gran variedad, desde el propio observador hasta el fenómeno observado pasando por el modo de hacerlo o instrumento utilizado. Todo ello sin embargo forma parte de la investigación y debemos saber como afrontarlos de la mejor manera.

Como conclusión se puede decir que la observación directa es el método más fiable, pero solo se puede hacer con variables que sean observables y esto no es sino el registro visual de lo que ocurre en una situación real, consignado con algún esquema previsto, y según el problema del estudio.
En primer lugar hay que explicar las diferencias entre una entrevista y un cuestionario ya que se trata de fuentes de información distintas, en una entrevista la respuesta es más abierta, da lugar a varias interpretaciones, es más subjetiva. En el cuestionario en cambio la mayor parte de las preguntas tiene un numero de respuestas limitado. No obstante ambas fuentes de información tienen una serie de ventajas e inconvenientes de gran utilidad a la hora de elaborar un protocolo o trabajo de investigación.
Dentro de la entrevista nos encontramos con una amplia gama de elección de cara a la elaboración, por un lado las estructuradas que son fáciles de elaborar y no precisan de un entrenamiento previo del entrevistador o investigador en nuestro caso. Y por otro las no estructuradas en las que se puede profundizar más en el tema y se obtienen variables y orientaciones sobre las hipótesis. Ambas tienen como inconvenientes que precisan de mucho tiempo de preparación y una cierta imposibilidad de acceder a información confidencial del usuario.
Por otro lado, los cuestionarios son instrumentos de fácil acceso a determinada información sobre la población, tienen bajo costo y nos permiten obtener información sobre un mayor número de personas en un tiempo inferior a la entrevista. Finalmente se encuentra el registro del propio paciente, por ejemplo queremos hacer un estudio sobre hábitos nutricionales y le decimos al paciente que vaya registrando lo que va comiendo a lo largo de la semana otro ejemplo sería su registro diario sobre la glucemia. También podemos obtener la información de un informador directo: no es el paciente sino una persona que se hace cargo de él; los tutores de un niño, el cuidador o cuidadora etc.
¿Errores que se pueden cometer? Hay gran variedad, desde el propio observador hasta el fenómeno observado pasando por el modo de hacerlo o instrumento utilizado. Todo ello sin embargo forma parte de la investigación y debemos saber como afrontarlos de la mejor manera.
Como conclusión se puede decir que la observación directa es el método más fiable, pero solo se puede hacer con variables que sean observables y esto no es sino el registro visual de lo que ocurre en una situación real, consignado con algún esquema previsto, y según el problema del estudio.
jueves, 26 de marzo de 2015
TEMA 3. LA ETAPA CONCEPTUAL DE LA INVESTIGACIÓN
Durante este tema hemos aprendido la importancia que tiene averiguar cuál es el tema por el que debemos empezar a investigar, es decir, la identificación y valoración del problema.
 En primer lugar, lo que hay que tener en cuenta para una buena investigación es tener buenas ideas, esto depende del profesional que las genere y de los interrogantes que se haga. Además es imprescindible actualizar las informaciones y conocimientos que existen del tema en el momento previo a realizar la investigación pues pueden que éstas hayan sido modificadas desde que se empezó a estudiar.
En primer lugar, lo que hay que tener en cuenta para una buena investigación es tener buenas ideas, esto depende del profesional que las genere y de los interrogantes que se haga. Además es imprescindible actualizar las informaciones y conocimientos que existen del tema en el momento previo a realizar la investigación pues pueden que éstas hayan sido modificadas desde que se empezó a estudiar.
Tras ello, debemos establecer el marco teórico e identificar las variables a definir. Una vez hecho esto, hay que plantar el número de individuos a los que vamos a someter a dicha investigación, medir las variables con la mayor exactitud y precisión posible, plantear una estrategia de análisis y finalmente interpretar los resultados con precaución para que cuando los comuniquemos sea una información viable y de calidad.
 Por otro lado debemos tener en cuenta a la hora de elaborar un caso de investigación si las variables son factibles de medir, el tiempo hasta la aparición del resultado es el adecuado, la oportunidad que existe de conseguirlo, la disponibilidad de los sujetos, la posible colaboración con otros profesionales, los recursos económicos existentes, así como la experiencia del equipo investigador y el interés que tiene socialmente.
Por otro lado debemos tener en cuenta a la hora de elaborar un caso de investigación si las variables son factibles de medir, el tiempo hasta la aparición del resultado es el adecuado, la oportunidad que existe de conseguirlo, la disponibilidad de los sujetos, la posible colaboración con otros profesionales, los recursos económicos existentes, así como la experiencia del equipo investigador y el interés que tiene socialmente.
Tras ello, debemos establecer el marco teórico e identificar las variables a definir. Una vez hecho esto, hay que plantar el número de individuos a los que vamos a someter a dicha investigación, medir las variables con la mayor exactitud y precisión posible, plantear una estrategia de análisis y finalmente interpretar los resultados con precaución para que cuando los comuniquemos sea una información viable y de calidad.
Por otro lado debemos tener en cuenta a la hora de elaborar un caso de investigación si las variables son factibles de medir, el tiempo hasta la aparición del resultado es el adecuado, la oportunidad que existe de conseguirlo, la disponibilidad de los sujetos, la posible colaboración con otros profesionales, los recursos económicos existentes, así como la experiencia del equipo investigador y el interés que tiene socialmente.
Esto último tiene gran importancia ya que debemos pensar en los beneficios que pueden derivarse de nuestra investigación, las aplicaciones prácticas que se pueden sacar y el interés social que genere.
Espero que esta entrada os haya sido de utilidad y que lo tengáis en cuenta a la hora de iniciar un proceso de investigación.
Os dejo algunos enlaces en los que podéis buscar fuentes de información fiables.
http://www.ncbi.nlm.nih.gov/pubmed/
http://dialnet.unirioja.es/

Os dejo algunos enlaces en los que podéis buscar fuentes de información fiables.
http://www.ncbi.nlm.nih.gov/pubmed/
http://dialnet.unirioja.es/
sábado, 21 de marzo de 2015
TEMA 2. FASES DEL PROCESO DE INVESTIGACIÓN
En el
segundo tema de la asignatura, hemos estudiado las diferentes etapas
del proceso de investigación, que son la etapa conceptual en la que
nos preguntamos qué investigar y cómo hacerlo por otro lado la
etapa empírica en la que decidimos cómo investigar y que método
emplear y finalmente, la etapa interpretativa, en la que intentamos
encontrar el significado de los hallazgos obtenidos en la
investigación. Cada una de estas etapas consta de diferentes
apartados y/o pasos, que debemos seguir para la realización de un
informe o investigación.
Por
otra parte, también hemos identificado los distintos errores y
sesgos que pueden cometerse a lo largo del proceso de investigación,
los cuales tendremos que intentar evitar para que el proceso de
investigación sea válido o lo más óptimo posible. Es importante
resaltar que hemos aprendido la diferencia entre precisión y
exactitud, que a pesar de no ser lo mismo, es muy primordial que
vayan unidas en la investigación. Para ello debemos seleccionar
las medidas más objetivas posibles. Por ejemplo es mejor preguntar,
cuantos cigarrillos fumas, que si preguntas eres fumador? Porque
puede haber gente que fume 5 cigarrillos al día y no se sienta
fumador.

Para
finalizar el tema, hemos estado comentando acerca de la importancia
de la ética en la investigación, algo muy importante que nunca
debemos olvidar a lo largo de toda nuestra carrera como futuros
profesionales de la salud.
En
conclusión, el segundo tema de la asignatura ha sido bastante
productivo y práctico, ya que nos ha brindado la posibilidad de dar
nuestros primeros pasos en un gran campo como es la investigación.
Ejemplo de
sesgo:
Un
equipo de atención primaria investiga la calidad de atención
percibida por la población beneficiaria aplicado a un cuestionario a
toda la población atendida en un mes en el centro de salud. El
resultado revela que el 95% de los encuestados califica la atención
con una nota de 7.

- Sesgo de selección: Se recurre a la información de personas que pueden no haber ido durante un mes. Es más evidente en este caso.
- Sesgo de clasificación: Error a la hora de elegir el método para recoger información, en este caso, un cuestionario. Para no tener este error, hay que hacer un muestreo aleatorio. Es la única garantía de que la selección sea más efectiva.
Suscribirse a:
Entradas (Atom)